Protect PII information in your Microsoft Fabric Lakehouse with Responsible AI



Organizations, data analysts and data scientists need to protect the personally identifiable information (PII) of their clients, such as names, addresses, emails, phone numbers, or social security numbers (SSN), that they use to build reports and dashboards. PII can pose risks to both the data subjects and the data holders and can introduce security breach vulnerability, privacy violations or biases that affect the decisions made based on the data. For example, if a source data contains PII in a generative AI application, there’s a risk of confidential information such as a bank account information to be returned from a user’s prompt inquiry. One way to protect PII is to use responsible AI, which is a set of principles and practices that help to mask PII with synthetic or anonymized data that preserves the statistical properties and structure of the original data but does not reveal the identity or attributes of the individuals.
Let’s look at a scenario with Contoso Bank, which is a fictitious bank that holds a dataset of their customers who apply for different kinds of credit: home loans, student loans, and personal loans. They want to use analytics and machine learning techniques to make data-driven decisions, but they also want to ensure that the security and privacy of their customers is not violated by someone accessing their PII information through a Generative AI Search. Moreover, they want to avoid any biased decisions based on sensitive features such as age, gender, and ethnicity in an AI Loan approval case. To achieve these goals, they need to use Responsible AI practices that protect the PII and sensitive features in their dataset, such as data masking, secure and compliant data storage and access, fairness and accuracy monitoring, and transparent and respectful communication.
One possible way to use Azure AI to identify and extract PII information in Microsoft Fabric is:
Use Azure AI Language to detect and categorize PII entities in text data, such as names, addresses, emails, phone numbers, social security numbers, etc. The method for utilizing PII in conversations is different than other use cases, and articles for this use are separate.
1 – Load Dataset into your Lakehouse
The foundation of Microsoft Fabric is a Lakehouse, which is built on top of the OneLake scalable storage layer and uses Apache Spark and SQL compute engines for big data processing. A Lakehouse is a unified platform that combines: The flexible and scalable storage of a data lake and the ability to query and analyze data of a data warehouse.
- In the Lakehouse explorer, you see options to load data into Lakehouse. Select New Dataflow Gen2. If you haven’t created a Lakehouse, follow these steps to create one.
- On the new dataflow pane, select Import from a Text/CSV file.
- On the Connect to data source pane, select the Upload file radio button. Drag and drop your file as your DataSource. After the file is uploaded, select Next.
- From the Preview file data page, preview the data and select Create to proceed and return back to the dataflow canvas.
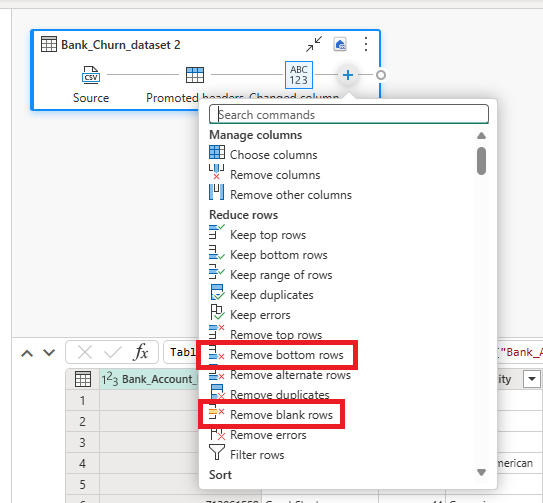
- From the dataflow canvas, you can easily transform the data based on your business requirements. Click on the + sign and add the Remove blank rows and the remove bottom rows commands. Specify the number of rows you want to remove.
Note: if you have a large file the Azure AI Language service won’t be able to analyze and identify the PII information in your table. Read more on character and document limits here - Select Publish once done.
- Navigate back to your Lakehouse, then select the 3 dots next to the Tables folder and select Refresh. You will notice that our table has been loaded into the Lakehouse for use. You will also notice the PII data in the table because we have not masked it yet.
2 – Transform the data by identifying and masking/extracting the PII
To mask and identify the PII information from the dataset, you can use the Azure AI Language service that has the PII extraction feature that you can leverage. Then you will have to call this feature with your Microsoft Fabric Notebook in your Lakehouse. This can be achieved through:
- Create an Azure AI Language resource, which grants you access to the features offered by Azure AI Language. It generates a key and an endpoint URL that you use to authenticate API requests. This will be used later in the blog.
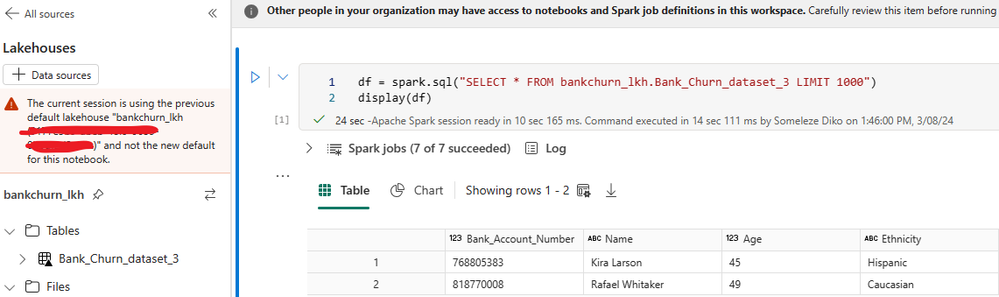
- In your Lakehouse, select the dataset/table and click on the 3 dots next to it. Choose Open Notebook then choose New Notebook. This will load your notebook where you can transform your data and start using the PII information feature.
- Choose Lakehouse on the left-hand side pane, this will add a new code cell in your notebook. The code cell will query and display your data in a data frame.
- Add a new code cell and paste the following code. This code will enable you convert your data frame into a serializable json to send as part of the request to the PII feature in the Azure AI Language service. You will get a JSON object as an output in which you extract the redacted text (i.e your data with masked PII information). The PII service supports different SDKs and client library languages such as C#, Python, JavaScript and Java. For this blog we will use the REST API to access the service.
import requests
import pandas as pd
import json
request_url = 'https://[Your_language_service].cognitiveservices.azure.com/language/:analyze-text?api-version=2023-04-01'
access_key = 'Your_Language_Key_Here'
pandas_df = df.toPandas()
json_df = pandas_df.to_json()
#Set request data and headers
request_data = {"kind": "PiiEntityRecognition", \
"parameters": {"modelVersion": "2023-09-01"},\
"analysisInput": {"documents": [{"Id":1,"language":"en","text":json_df}]}}
request_headers = {"Content-Type": "application/json",
"Ocp-Apim-Subscription-Key": access_key}
#Store the request results and display them on Success
response_data = requests.post(request_url,json=request_data,headers=request_headers)
if response_data.status_code == 200:
print(response_data.text)
else:
print(response_data.status_code)
- Add a new code cell and add the following code in the cell. This will allow you to select a specific property within the output of the previous step. To select keys (the desired output) from the object you need to convert the output of the selected property into a list.
#Convert the json string into an Object and select the results key json_output = response_data.json() json_results = json_output['results'] #Convert the JSON string in json_results to select the keys redactedText key and store into a new dataframe results_list = list(json_results.values()) redactedtext = results_list[0][0]['redactedText'] display(redactedtext)
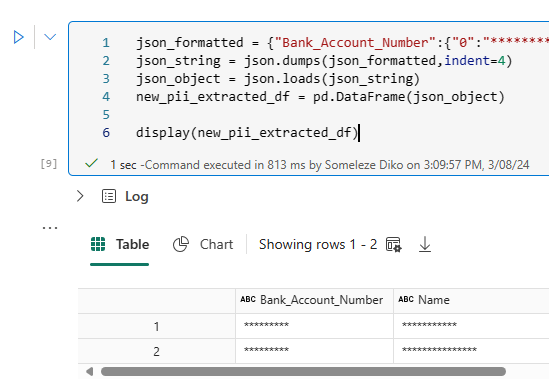
- Add a new code cell and add the following code in the cell. You have to note that the output of the previous step is not in the correct JSON format so you will need a JSON formatter that you can use so that you have the correct format that can be used as a schema for your new data frame.
json_formatted = {"Your_formatted_JSON_here"}
json_string = json.dumps(json_formatted,indent=4)
json_object = json.loads(json_string)
new_pii_extracted_df = pd.DataFrame(json_object)
display(new_pii_extracted_df)
The output would look like this, and you can notice that in the new data frame the PII information is masked.
- Lastly, you can create a new table with the PII information masked using the following code. After this cell has run, you can refresh the tables folder in the Lakehouse to see the new table.
from pyspark.sql import SparkSession
spark_df = spark.createDataFrame(new_pii_extracted_df)
spark_df.write.mode("append").saveAsTable("PII_Extracted_Bank_Churn_dataset")
display(spark_df)
3 – Copy the data to a target DataSource
It is natural to want to move your transformed data into another DataSource like a vector database (e.g. Azure cosmos DB) and to achieve this within Microsoft Fabric you can build a pipeline that copies the data. This part of the blog assumes that you have an Azure Cosmos DB setup in the Azure Portal
To achieve this, you can use Pipelines and Azure Cosmos DB by following these steps:
- In your Workspace, click on + New button and select Data Pipeline while giving your pipeline a name the select Create.
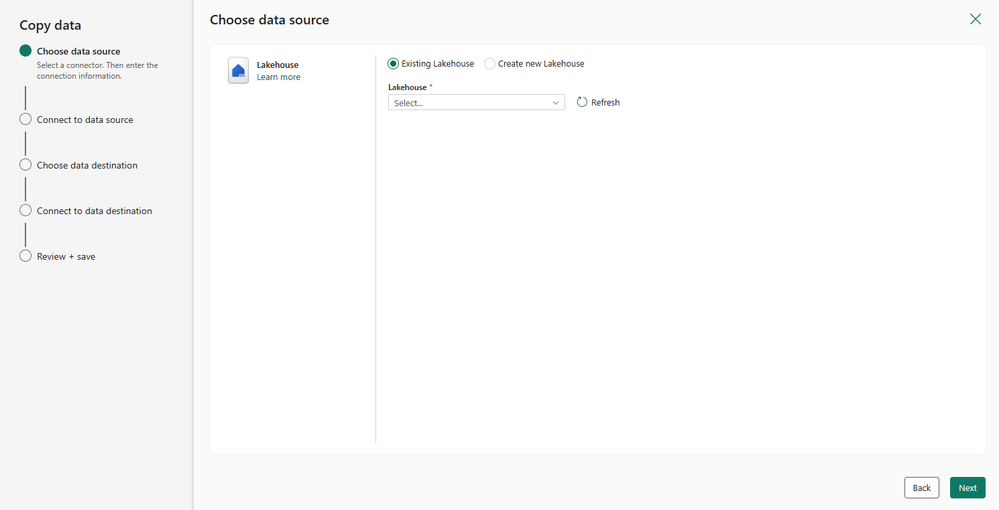
- In pipeline canvas select Copy Data
- Next you will have to choose the connector for the DataSource you will copy data from. In this case, you can choose Lakehouse then select Next. In the next screen, you will have to specify the Lakehouse details then select Next.
- On the next screen, choose the table you created and masked the PII information in the Notebook then select Next.
- The next step is to choose the data destination where you will store the copied data in, here you can choose Azure Cosmos DB then select Next.
- On the next screen, you will have to specify your destination data source connection. You can create a new connection if you don’t have an already existing one. The Cosmos DB endpoint and Account Key can be access in the Azure Portal. Once done, you will have to choose the Database in your Azure Cosmos DB then select Next. After that you will have to choose the Container that you have in your database then select Next.
- Once you have chosen your container, you will have the option to edit and check column mappings. You can select Next, there are no changes needed here.
- On the Review + save screen, check if everything is correct then select Save + Run. This will start the copy process and copy your data into your target DataSource.
Conclusion
The PII feature in the Azure AI language service enables you to mask the PII information in your dataset before you can use it in your Machine Learning/AI models. You can also use this feature with Microsoft Fabric so that you can work with cleansed data and build reports and dashboards that do not expose PII information within your dataset.
To learn more about Microsoft Fabric, you can join this Cloud Skills Challenge.

